
 project
project
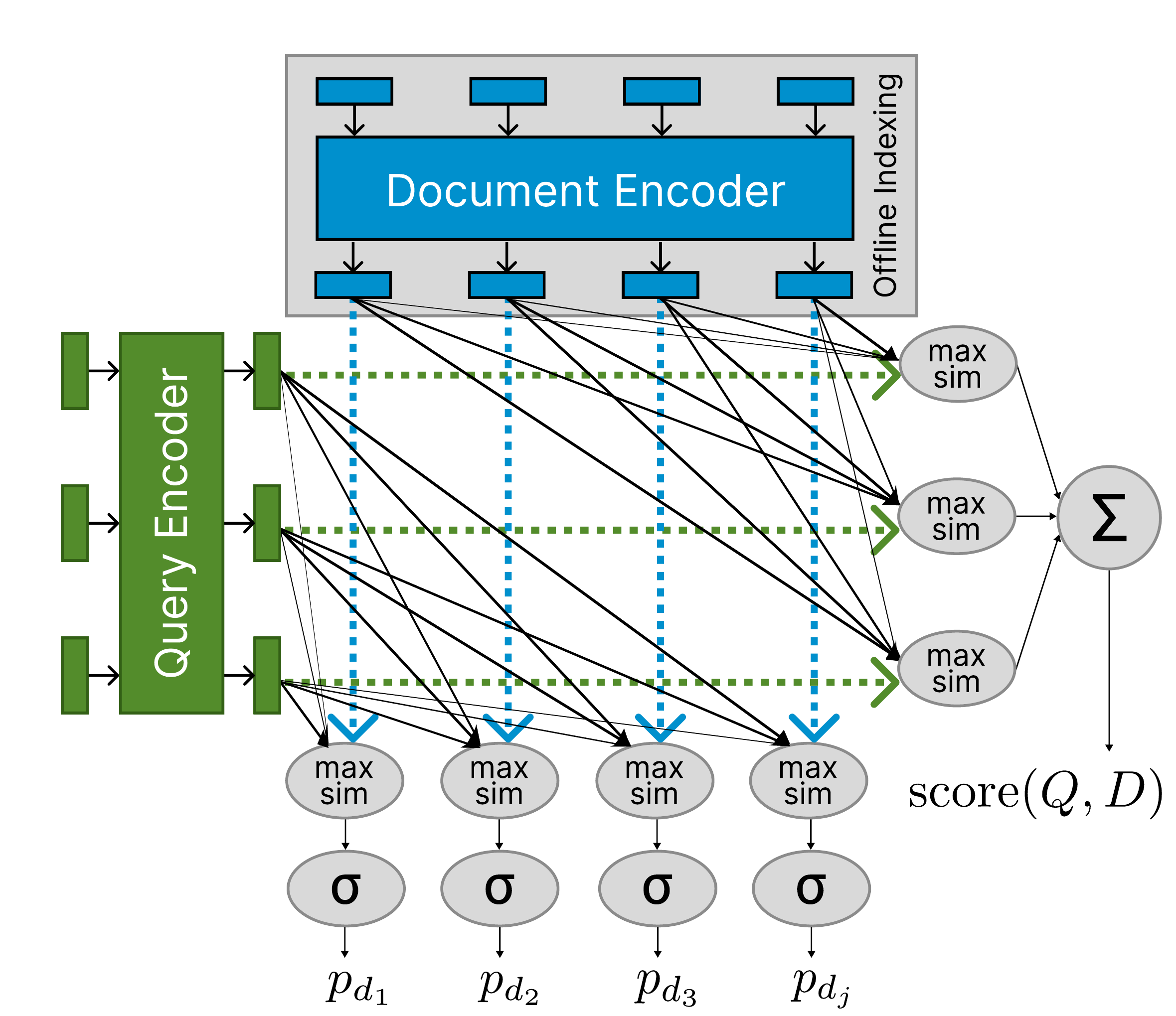
An extension of ColBERT that scores each document token for relevance during retrieval, using span supervision distilled from Gemma 2 on MS MARCO, so you get evidence-style highlights without a second LLM call.
NLP
Retrieval
ColBERT
XAI

