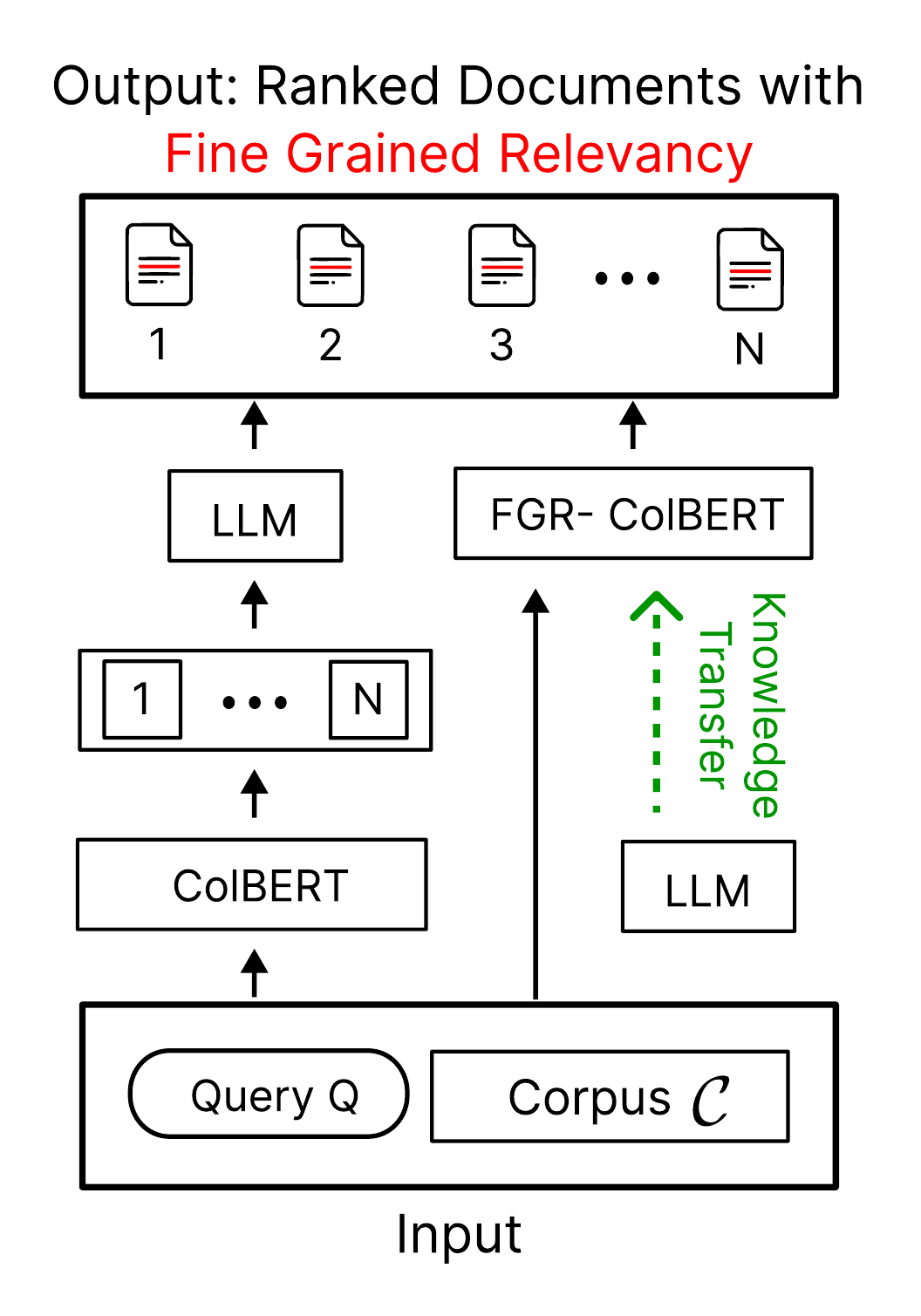
Satisfying nuanced user queries
Finding relevant information for a user can be broken down into two steps:
- find the relevant document,
- find the information within the document.
One possible way to implement such a system is to solve the first problem with a document retriever and then use an LLM to pinpoint the most relevant spans inside each document.
However, running an LLM on every query–document pair at request time is often impractical, and the work grows quickly when you need highlights across many documents.
To address this, we propose FGR-ColBERT, a modification of ColBERT producing Fine-Grained Relevance signals directly during retrieval (cf. Figure 1a).
Prior work has shown that lightweight token-to-token interaction can model relevance scores for query–document pairs very effectively.
Here we build on that idea by estimating, for each document token, the probability that it is relevant given the query.
Modifying ColBERT architecture to model fine-grained relevance
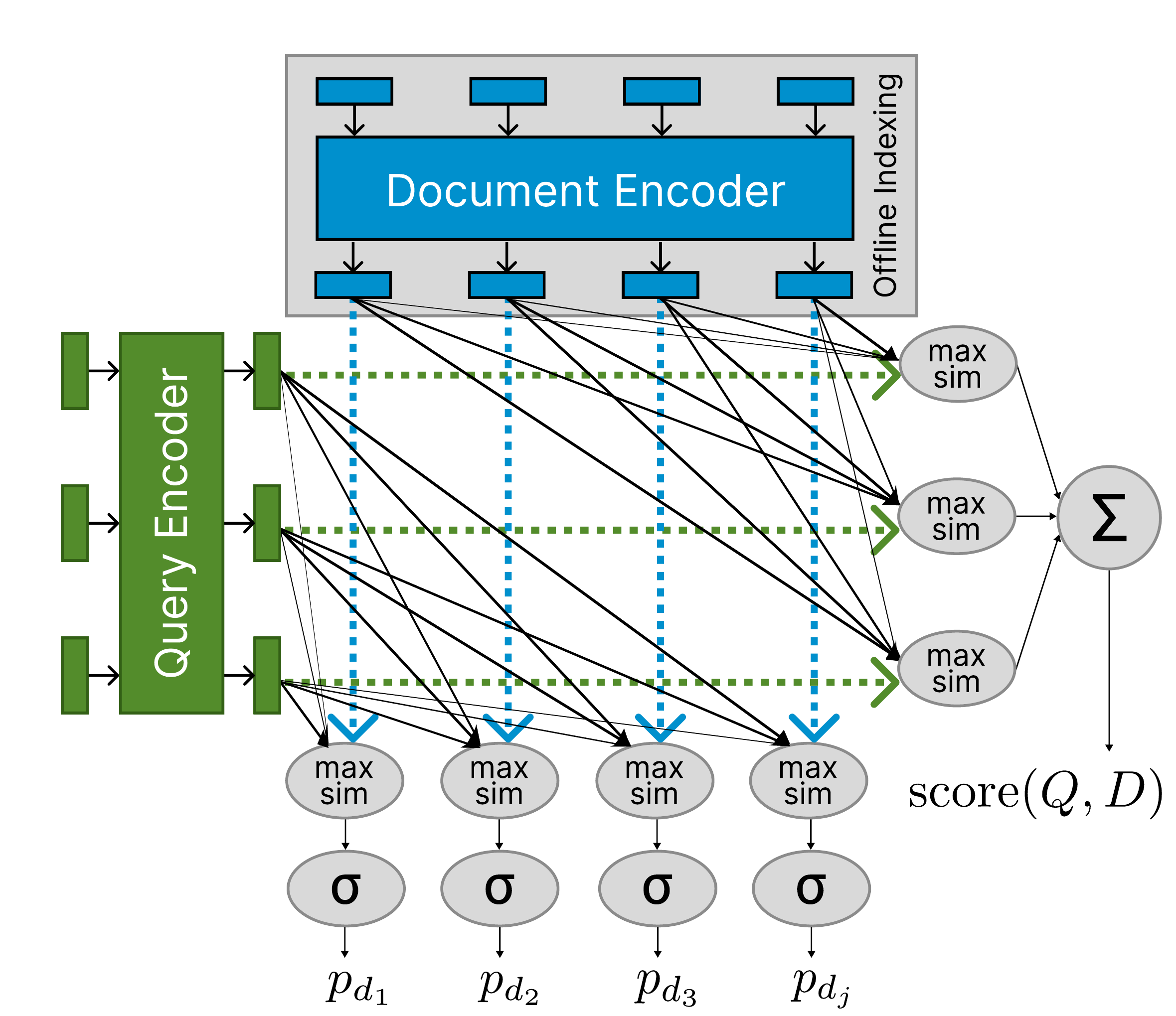
Standard ColBERT scores a document by matching each query token to its most similar document token (late interaction). The relevance score is the sum–max late interaction from the preprint:
where \(q_i\) and \(d_j\) denote the tokens in the query and document, and \(E_{q_i}\), \(E_{d_j}\) are L2-normalized contextual embeddings.
The core of FGR-ColBERT is to use ColBERT’s interaction orthogonally: for each document token, we take the max similarity over query tokens and pass it through a sigmoid:
Thresholding \(p_{d_i}\) yields token-level relevance.
The process is illustrated in this figure:
Supervision data obtained from LLMs
Instead of invoking an LLM while the user waits, we can run it offline on many query–passage pairs. With carefully designed prompts, the LLM approximates a span selection function: it marks which parts of the passage answer the query.
We use those token-level labels to supervise FGR-ColBERT with binary cross-entropy on document tokens. The full objective combines this term with the KL distillation loss from the ColBERT-v2 setup (cross-encoder teacher): L = L_KL + λ L_BCE. The BCE averages over document tokens with labels from the LLM (see the paper for the full expression). BCE is applied on positive passages only, which biases the model toward always seeking a relevant span, behaviour we find acceptable for this task.
Results
We use Gemma 2 to annotate the MS MARCO training split (and dev), producing MS-MARCO-Gemma-Train / MS-MARCO-Gemma-Dev. For human evaluation, three annotators labelled relevant spans on 140 query–document pairs sampled from MS MARCO dev. Retrieval numbers below are reported on the Gemma-dev retrieval split; plausibility is token-level F1 against human (or LLM) spans.
-
Plausibility (token-level F1 on human annotations): FGR-ColBERT reaches 64.51, compared with 62.82 for Gemma 2 (27B) and 51.67 for vanilla ColBERT, so a ~245× smaller model matches or slightly exceeds the teacher it was distilled from on this metric (difference valid as hypothesis checks on 140 pairs).
-
Retrieval: ColBERT attains Recall@50 = 98 on this setup; FGR-ColBERT reaches 97.12, i.e. about 99% relative retention while adding fine-grained scores.
Conclusion
We extend ColBERT so that token-level relevance signals from an LLM are folded into retrieval, not deferred to a second stage. On MS MARCO, FGR-ColBERT matches Gemma 2–level span plausibility on our human subset and keeps ~99% of Recall@50.
Questions? Feel free to reach out.
Interested in more details?
paper-preprint